PowerExpect
Posted on October 13, 2025 • 26 min read • 5,468 wordsA fast and simple app for viewing forecast and actual electricity prices for French and German/Luxembourg bidding zones.
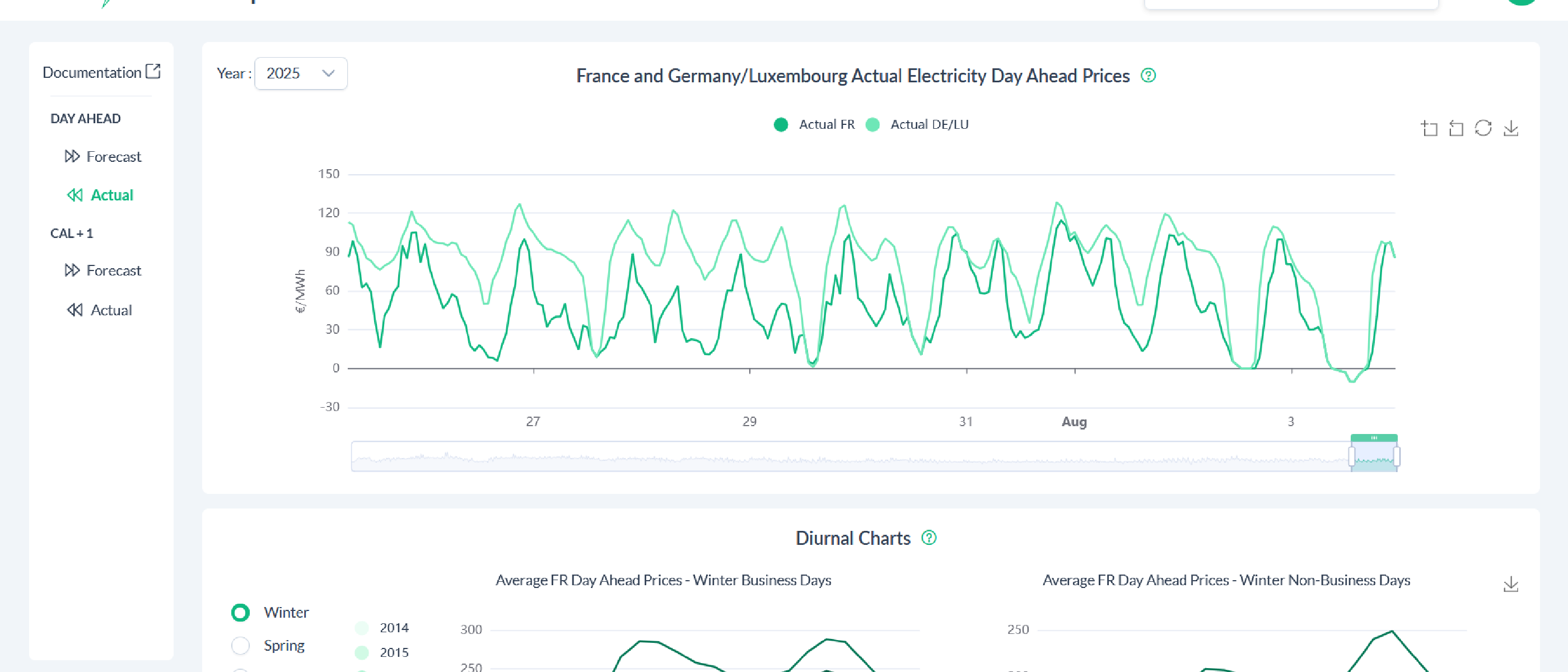
Open App
1. Motivation
The initial goal of this project was twofold: on the one hand, to learn a framework specialized in frontend development, and on the other hand, to test new methods/architectures for time series forecasting applied to electricity price forecasting.
Python frontend libraries are often limited and/or slow. I therefore wanted to test a framework specialized in frontend development for web applications. I chose Vue.js, which seemed to be the most accessible option.
I also wanted a comprehensive tool that would allow me to easily test new methods and models for time series forecasting, particularly electricity price forecasting, in real-world conditions. When working on this type of project in industry, you generally prefer to use what you know already works well, following Occam’s razor and under time constraints. This often leaves little room for in-depth exploration of new things. However, there is a wealth of literature on the subject, making me very curious.
2. Introduction
Electricity Price Forecasting (EPF) is a well-known application of Time Series Forecasting (TSF) methods. This question has been explored for over 30 years now, since the wave of electricity market liberalisation in the 1990s, and is attracting increasing interest in the literature [1]. Firstly because TSF itself is attracting growing interest [2] and secondly because EPF plays a fundamental role in energy markets, enabling market players to optimize their trading strategies, reduce financial risks, and maintain grid stability [3]. However, this is a complex (and increasingly so) exercise because short-term price fluctuations are highly sensitive to renewable energy generation forecasts, regulatory and geopolitical announcements, and unforeseen disruptions such as generation outages or grid constraints. This results in prices with high volatility, non-linearity, and sudden spikes [3]. There are several EPF methods, but only those involving Machine Learning (ML) are of interest here.
The history of EPF has closely followed the history of TSF. TSF began with statistical methods based on moving averages developed in the 1950s to 1970s (exponential smoothing/ARIMA). It then continued with the first ML methods such as decision trees in the 1980s, followed by GBM (Gradient Boosting Machines) in 1999/2001. At the same time, deep learning (DL) models appeared with RNNs and LSTMs in the 1990s [2].
These fundamental building blocks were subsequently expanded, improved, and combined to create the wide variety of architectures we have today. Popular implementations of GBM such as XGBoost and LightGBM, which were not specifically designed for time series forecasting, appeared in the 2010s and quickly became standards in the field thanks to their performance and interpretability. Deep learning models have received increasing interest, with architectures based on MLP (Multi-Layer Perceptron) such as NBEATS and TIDE, and transformer-based architectures such as PatchTST and PETformer. Following the rise of foundation models for natural language processing, foundation models for time series forecasting have emerged, such as TimeGPT and Lag-Llama. Advances have also been made in other architectures, such as Mamba models, and in related areas such as feature engineering. Overall, TSF is a particularly dynamic and fruitful area of research, where many ideas show great potential [2].
The aim of EPF (and more generally of TSF) is to find a sufficient approximation according to certain metrics of the function:
With:
- = The past observations window size
- = Forecast horizon
- = Number of features
- = Number of features available during forecast ( )
- = Vector of past observations
- = The matrix of explanatory variables over time steps
- = The matrix of features over
- = The vector of the target variable forecast over
The choice of is an architectural choice. It is based on several factors, such as our knowledge of the field of application, our belief in the architecture’s ability to model the relationships between the features and the target variable for this problem, and our understanding of the literature.
In this project, the choice of is based primarily on my curiosity after reading a paper on EPF or TSF.
3. Workflow

The PowerExpect application has its backend on AWS and its frontend on Vercel. I wanted to have for this project an application that updates automatically every day, following the pace of day-ahead auctions. This meant I needed a machine that would launch every day, execute the code, and then save the results in a storage location accessible via an API by the frontend. I chose AWS, which I was already familiar with. The CI/CD pipeline is handled by CodePipeline and Codebuild, which automatically retrieve the code from my GitHub repository, then build the Docker image and store it in ECR. An EC2 instance is launched every day via a lambda controlled by EventBridge. The instance retrieves the image from ECR when it starts up and executes it. All updated inputs and outputs are saved in two separate private S3 buckets. The logs are also sent to my email address by the instance so that I don’t have to log in to AWS every time, which is a bit of a pain with MFA. The files on S3 can be large and exceed Amazon’s service limit. So I opted to download them directly to S3 from the frontend via 1-second pre-signed URLs served by an API.
4. Data
The day-ahead (or SPOT) price for each 15 minutes of the following day is determined by an auction for each market in Europe. There are therefore 96 auctions for the French zone and for the German zone. Participants have until noon to indicate the volumes they want to buy/sell based on the price. The price at time t will therefore be the intersection between the aggregate demand curves at t and the supply curves at t for each participant [4].
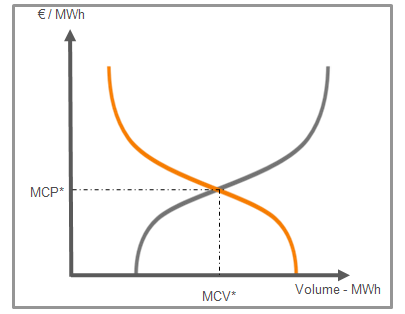
SPOT prices are therefore driven by supply (generation) and demand (consumption), which are themselves driven by numerous factors. The structure of the market in question, the composition of the electricity mix, the weather, balancing markets, operational constraints, the availability of power plants, seasonality/calendar (time, day, season, etc.), fuel prices, and CO2 quota prices all influence supply. Similarly, demand is influenced by seasonality/calendar and temperature effects, but also by other factors such as consumption habits [5].
CAL+1 prices, i.e. the series of prices for calendar contracts traded daily on exchanges in year Y for delivery in year Y+1, are currently being added.
Like any time series, prices are strongly correlated with previous values. An autocorrelation and partial correlation study on both markets makes it easy to select relevant lags. I have chosen lags common to both markets to simplify the pipelines.
For the time being, only the main and easily available influencing factors, such as generation and total demand, are used in order to limit the complexity of the models. Inevitably, this also limits their predictive power.
Data is primarily sourced from the great ENTSOE Transparency Platform . This data is accessible free of charge via an API. Models are trained on post-energy crisis data from 2022. The forecast horizon is currently one day, or 96 points.
5. NHITS
a. Architecture
N-HiTS, which stands for “Neural Hierarchical Interpolation for Time Series” [6], falls into the category of MLP-based DL architectures, which have now proven to be among the best options available. This model was introduced to overcome two typical problems in long-term forecasting: complexity, i.e. memory costs that explode with the size of the horizon, and forecast volatility, i.e. the difficulty of obtaining reliable and stable long-term forecasts.
To do this, the researchers started with the NBEATS model introduced three years earlier [7] and then improved it using two techniques: “Multi-rate Signal Sampling” and “Hierarchical Interpolation” [6].
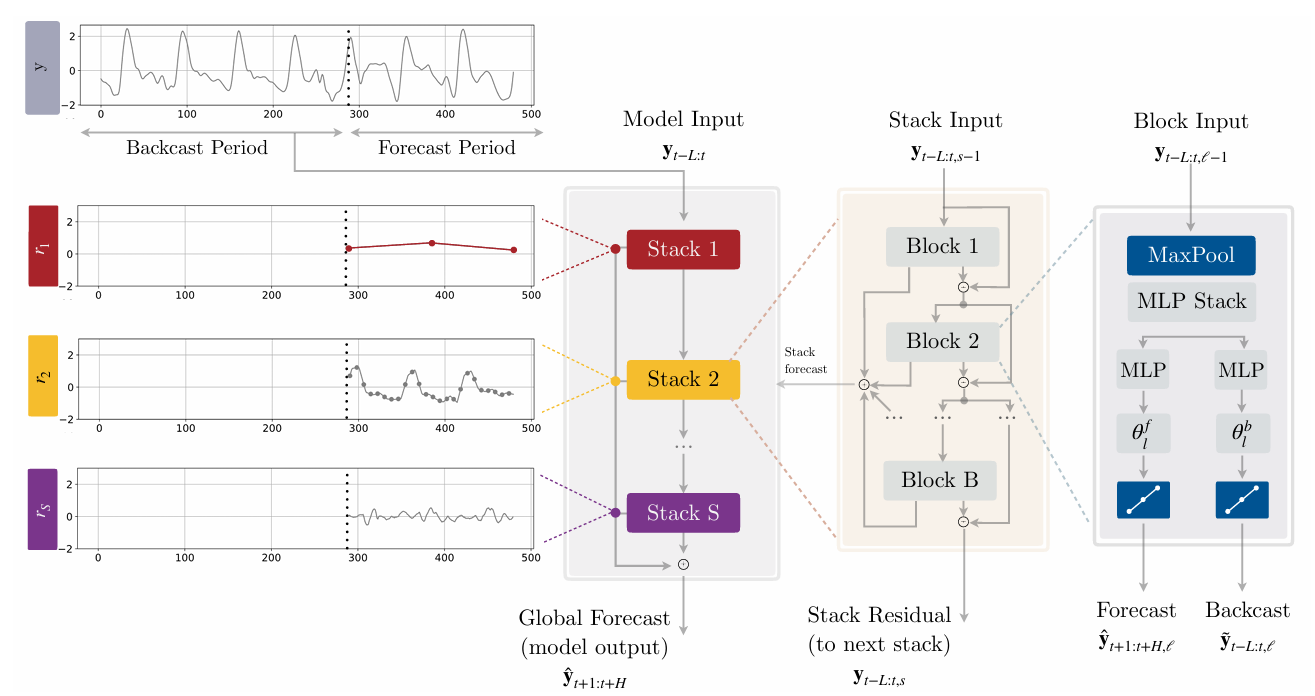
The figure above illustrates the univariate version of the N-HiTS architecture, which simplifies the equation of the problem posed in the introduction but is sufficient to understand how the model works (see NBEATSx for more information on incorporating exogenous variables into the architecture [8]). Thus, this version only takes as input the vector of past observations, denoted here as with being the number of lags. We can see that N-HiTS is based on a 3-layer architecture with S stacks, each composed of B blocks. The highest level layer corresponds to the overview with the arrangement of stacks, the next to the arrangement of blocks within each stack, and the last to the components within each block [6].
1st layer
N-HiTS is composed of S stacks, each of which models different frequencies of the time series. A stack takes as input the residual of the previous stack (except for the first stack of course, which takes directly) and returns its forecast and its residual . The forecasts of each stack are added together to form the final forecast (the model also returns the residual of the last stack S ) [6]:
2nd layer
Similar to stacks (and comparable to boosting models), the B blocks of a stack s are assembled hierarchically, where the input of block is the residual of block . In fact, the backcast output of a block denoted is used to clean the input of the next block. This allows the blocks to focus their attention on parts of the series that are not understood. The forecasts of each block are added together to form the final forecast of the stack [6]:
3rd layer
Each block begins with a max pooling layer with filter size followed by an MLP. The pooling step allows the block to focus on a specific frequency of the input series. A large will filter out high frequencies, forcing the MLP to model a low-frequency series, and conversely, a small will force the MLP to model a high-frequency series. This is called “multi-rate signal sampling”. This step has two advantages: First, it allows the model to focus on low-frequency aspects of the time series, which produces more stable and consistent long-term forecasts. Second, it reduces the size of the MLP input, thereby decreasing the complexity of the calculation (and thus improving training speed) and the risk of overfitting. With as the input vector of block , we have [6]:
Block will then use the reduced input to estimate the backward interpolation parameters and forward interpolation parameters by estimating the hidden vector with an MLP and then projecting it linearly [6]:
Finally, the output vectors of block and are computed by “hierarchical interpolation” [6].
Once the coefficients and have been computed, it is necessary to restore the initial sampling rate or granularity (modified by the max pooling/multi-rate signal sampling operation) in order to predict all H points in the forecast horizon. To do this, N-HiTS performs “temporal interpolation” using the interpolation function [6]:
can take the form of a nearest neighbor function, piecewise linear, or cubic. The authors of N-HiTS indicate that, on average across all tested datasets, prediction accuracy and computational performance favor the linear method, where is expressed as [6]:
With:
The time partition used to calculate is defined as where is called the “expressivity ratio” and controls the number of parameters per unit of output time: (smallest integer greater than or equal to ). Using this ratio and temporal interpolation avoids the explosion in memory cost and computational complexity that occurs as the horizon increases, a recurring problem in other architectures such as transformers.
N-HiTS will force the expressivity ratio to synchronize with the size of the filter used in multi-rate signal sampling, and this is where the power of the architecture lies. Considering a top-down approach (which proves to be more effective than a bottom-up approach on the datasets tested in the paper), i.e. by choosing increasing and therefore decreasing , the blocks will learn both to observe and generate signals with increasingly fine granularity/frequency. This approach, which prioritizes the specialization of each block and therefore each stack in a specific frequency, is called “hierarchical interpolation”. By cleverly choosing the , we can match the frequency of the blocks with known cycles in the time series, such as months, weeks, days, etc [6].
In short, N-HiTS is a generalization of N-BEATS that offers accurate, interpretable, stable forecasts across all horizons, while minimizing memory costs and training time. N-HiTS greatly enhances the power of MLP-based architectures.
With the recent switch in October 2025 from hourly to 15-minute intervals for European day-ahead markets, thereby multiplying the forecasting horizon by 4, the use of models designed for long-term forecasting such as N-HiTS has undoubtedly become more relevant.
b. Hyperparameters
Hyperparameters are fine-tuned using the tree-structured Parzen estimator (TPE) approach [9] implemented in hyperopt (see section “built with”).

c. Training
6. HSL
a. Architecture
Hybrid or ensemble models, which combine several models and methods, are a solid choice for EPF/TSF [3]. They are particularly effective at capturing the complex, nonlinear, and volatile dynamics of electricity markets by leveraging the strengths of multiple architectures. The paper presenting the following model provides an example of combination that can be used specifically for EPF [10].
HSL stands for “Hybrid Stacking Lasso” and is a hybrid model combining six base models: XGBoost, CatBoost, LightGBM, LSTM, GRU, and NODE. These basic models are combined by stacking, using Lasso regression as the meta-model [10].
Each base model has its strengths: XGBoost is robust on structured data and has a good ability to capture nonlinear interactions. LightGBM is effective on large datasets, enabling fast training and good temporal feature extraction. CatBoost performs well in its handling of categorical variables and its resistance to overfitting. LSTM and GRU are included for their ability to model long-term temporal patterns. NODE, by combining decision trees and neural networks, can capture complex and nonlinear interactions on tabular data [10].
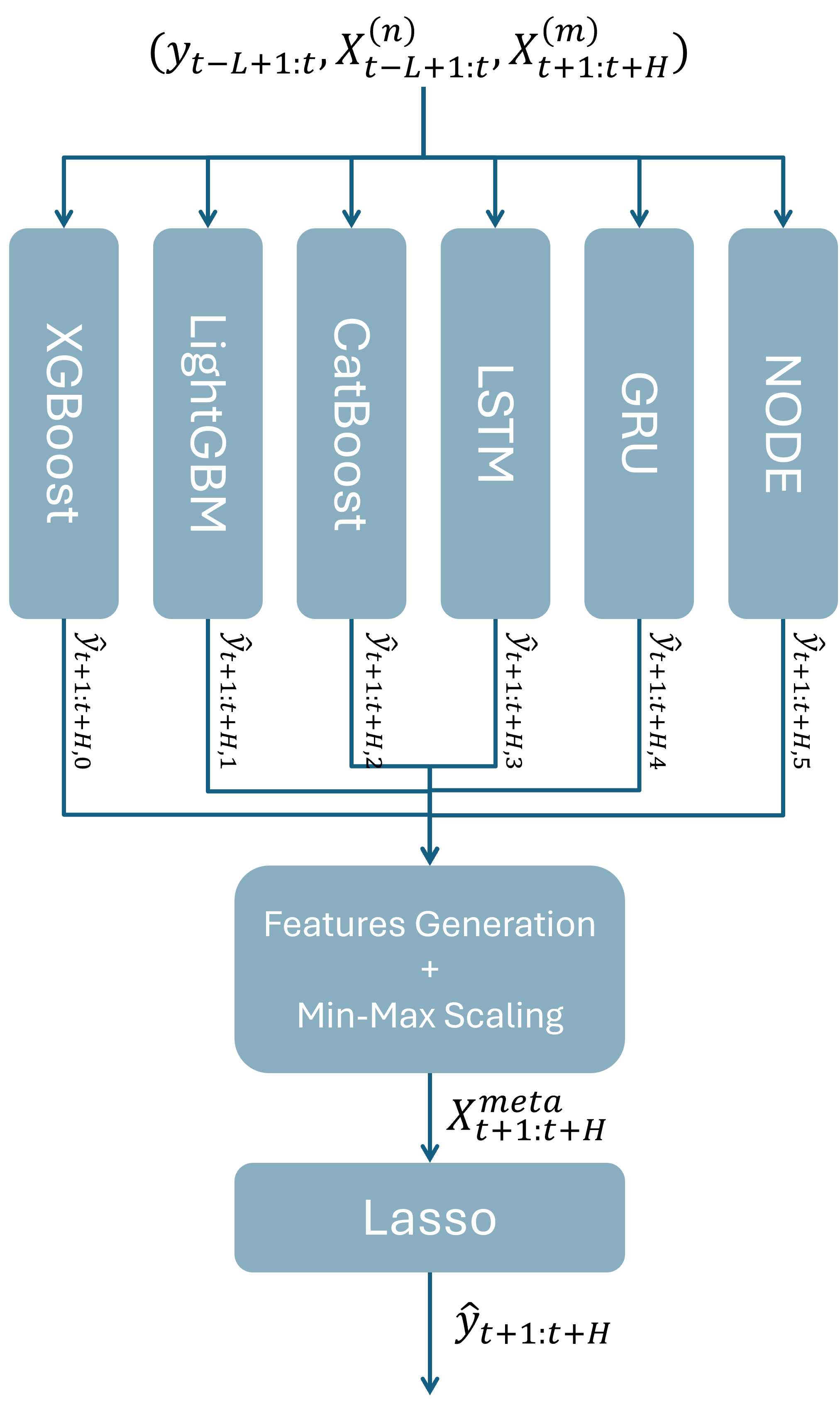
The forecasts of each base model are concatenated and then normalized to using Min-Max scaling:
Next, the matrix with the scaled forecasts is augmented with temporal variables (hours, days, weeks, etc.) to form the meta-feature matrix used as input for the meta-model. The article introducing HSL does not provide any information on the strategies to be used to train the meta-model. This leaves us free to test different things while respecting the philosophy of the original paper. I therefore followed some of the recommendations in Jason Brownlee’s cool article on stacking algorithms [11]. For example, he points out that adding other explanatory variables to the meta-model can provide it with additional context on the best way to combine the forecasts from the base models. Tests confirmed this approach. Furthermore, increasing the input size is not a concern when using Lasso regression as a meta-learner, since unnecessary variables will be dropped. The final forecast is written as:
With the weight vector of dimension H. This vector is found by minimizing the objective function over the training period where the Lasso term appears:
With:
- the loss function
- the regularisation parameter
- L1 norm applied to model weights
Lasso/L1 regularization sets weights to zero in directions where the cost function is not sensitive. Thus, it attempts to set parameters that are not very important to zero, which makes it possible to handle large input matrices and promotes a minimalist solution. Let’s now describe each base model in detail.
b. XGBoost
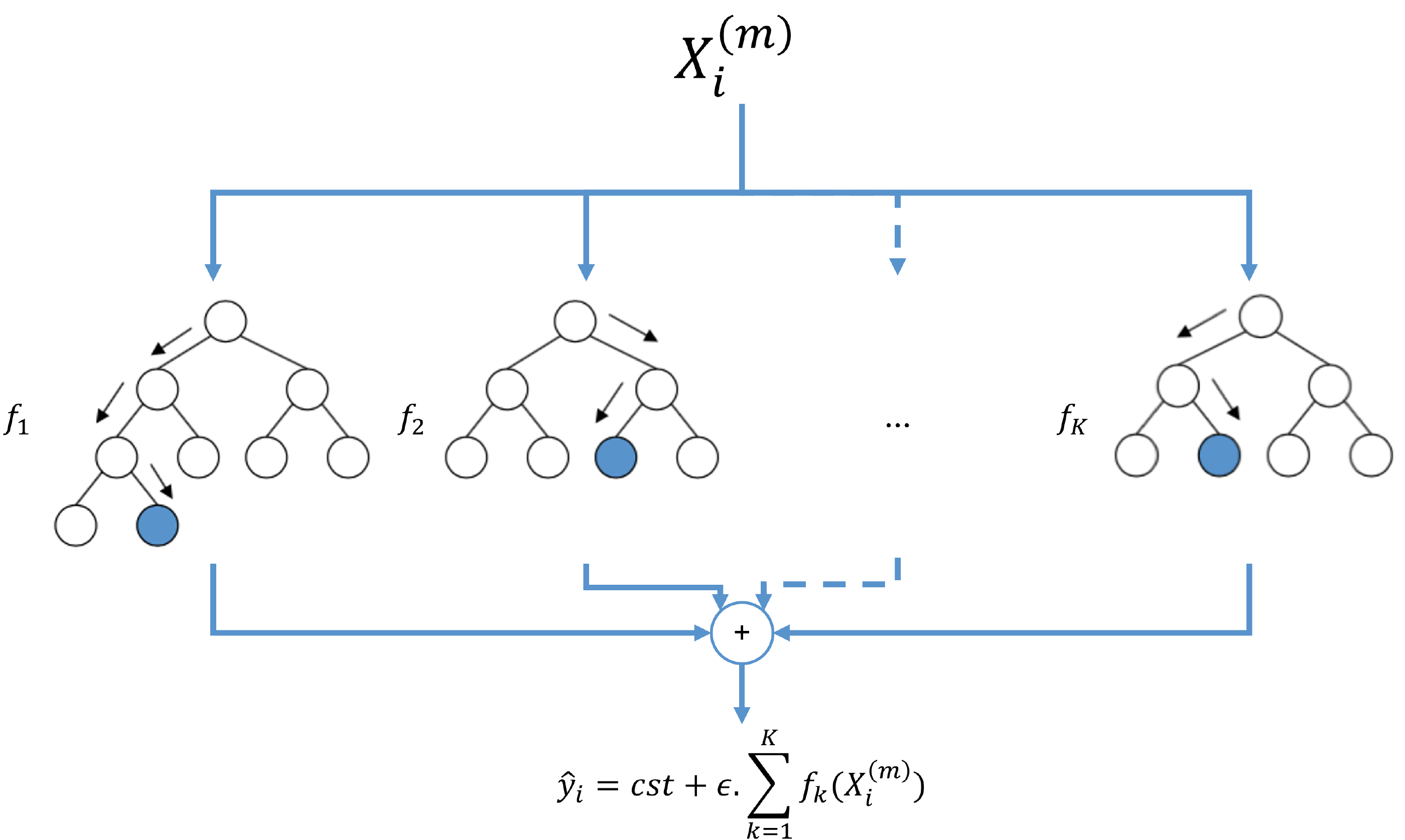
XGBoost, which stands for “Extreme Gradient Boosting”, is a machine learning architecture based on the GBMs mentioned in the introduction and developed at the beginning of the century. It is an ensemble model that uses CARTs (“Classification And Regression Trees”) called “weak learners” as base models. CARTs are similar to simple decision trees, except that a score is associated with each of the leaves/nodes, allowing them to handle regression problems with continuous variables.
As a reminder, a decision tree is a non-parametric (=there are no underlying assumptions about the distribution of errors or data and the model is based simply on the observed data) supervised learning method. They can be used to predict the value of a target variable by learning simple decision rules inferred from the data features. They are highly interpretable as they directly and visually illustrate the decision-making process. This interpretability is lost with most ensemble methods.
XGBoost combines trees through boosting, where the model’s forecast is equal to the sum of each tree’s forecast for each time step [12]:
With:
- = the number of trees.
- = the structure of the k-th regression tree.
- = the vector of the features at index .
- = the learning rate. The larger it is, the more trees will need to generalise in order to predict the residual, thus preventing overfitting.
- = the default forecast if the model didn’t have trees.
The functions to are learnt by boosting, adding one tree after another. Hence [12]:
Thus, the model will grow as trees are added, and each tree will learn to predict the residual of the previous tree. The objective function to be minimised in order to train the k-th tree is written as [12]:
With:
- the loss function.
- the regularisation function.
Let be the vector of weights for each leaf (where = number of leaves in the k-th tree) and the tree structure that associates the features to a leaf . We have: [12].
Furthermore, by considering ridge regularisation plus a term to encourage simple trees, we can write:
reduces the sensitivity of the weights to the observed values which limits overfitting.
Thus, by approximating using a second-order Taylor expansion and simplifying (= removing the sum of losses, which is a constant, and setting ), we get [12]:
With:
- the set of indices of the features associated with the j-th leaf.
- the i-th first-order gradient of the k-th tree or boosting iteration.
- the i-th second-order gradient of the k-th boosting iteration.
For a given structure , the optimal weight of the j-th leaf is then written as [12]:
And the optimal value :
The cost measures the performance of the tree structure by comparing the regularisation term on the number of leaves to the cost of each leaf. The smaller is, the better the tree structure performs [12].
If we used the mean square error as the loss function, then we would have et . So:
and:
Now, we need to test every possible structure, i.e. every possible split combination (= one parent or root node and two child leaves), and keep the one that offers the best performance (= smallest possible ). This search is costly in terms of complexity and potentially also in terms of memory, since the costs of each possible leaf and therefore their gradients ( ) must be computed.
XGBoost’s first approach is to use an exact algorithm (“Exact Greedy Algorithm”) that starts from a leaf and iteratively adds the branches of the best splits. It runs through all the sorted values of the features and accumulates the gradients, which allows it to lower the memory cost. To select the best split, the algorithm will choose the one that maximises the following score [12]:
The higher the score, the more the split lowers the cost of the tree.
Once the structure has been built, XGBoost will optimise it by removing splits that have a negative score. This tree pruning is controlled by the regularisation parameter
, which reflects a greater or lesser desire to have deep trees, i.e. a complex solution that is likely to overfit [12]. Other parameters can be used to manage the complexity of the model, such as max_depth, which limits the maximum depth of the trees.
Usually, XGBoost will use variants of the exact algorithm to find splits in a more optimised way. This is because the exact algorithm is computationally expensive and difficult to scale, as it tests all possible splits. For example, if the input data is too large, XGBoost will use an algorithm (“Approximate Algorithm”) that reduces the number of splits tested to well-chosen percentiles [12].
In summary, XGBoost will make a forecast by summing the forecasts of each tree for each time step. During training, the model is built by adding trees one after the other in a cumulative way. Each tree is built by starting with a root and then adding other leaves level by level. Leaf splits are chosen to maximise a score that represents the leaf’s contribution to error reduction. XGBoost uses different regularisation terms to avoid overfitting and limit model complexity, such as , a threshold below which the split is considered to contribute enough to error reduction.
As XGBoost is based on trees where specific features are chosen for its splits, we can deduce the weight of each of them in the foercast, which makes the model easier to interpret than other methods such as those based on neural networks. In addition to the founding paper [12], I recommend the video series from statquest for more details on XGBoost.
c. LightGBM
LightGBM, which stands for “Light Gradient Boosting Machine”, offers an optimised implementation of GBM similar to XGBoost (see previous section). This algorithm takes performance optimisation further than XGBoost by introducing two improvements called “Gradient-based One-Side Sampling” (GOSS) and “Exclusive Feature Bundling” (EFB) [13].
The challenge with GBM implementations is always the same: how to optimise split finding while maintaining maximum performance ? The natural approach is to reduce the number of candidate splits (by reducing the number of splits to be tested or by resampling the amount of observed data) and features tested. LightGBM uses the GOSS algorithm, which keeps all data with significant gradients (above a predefined threshold) and performs random sampling on data with low gradients. In addition to GOSS, LightGBM introduces the EFB algorithm, which groups certain features together, thereby reducing the search space for splits [13].
Another important feature of LightGBM is the way it builds its trees. Unlike other implementations such as XGBoost, which do so level by level, LightGBM builds its trees leaf by leaf, choosing (according to a criterion) the best next leaf to process. With an equal number of leaves, this approach tends to yield better results. See the library documentation (built with section) for more information on this subject [13].

d. CatBoost
CatBoost for “Categorical Boosting” is, like XGBoost and LightGBM, an implementation of a GBM (see the XGBoost section for notations). CatBoost stands out for its handling of categorical variables and its approach to boosting to solve target leakages [14].
Categorical Features
A categorical feature consists of a discrete set of distinct values called categories. For example in TSF, we sometimes consider times of day (morning, afternoon, evening, etc.). These categorical variables can provide a substantial gain in information. However, they require a crucial encoding step, i.e. transforming the categories into numerical values that can be understood by the model with minimal loss of information [14].
There are several methods for encoding categorical features . A classic encoding method is “one-hot encoding”, which consists of converting each category into a binary column vector (1 for indices where the category appears and 0 otherwise). Obviously, this method is quickly limited by the number of categories to be encoded. Another popular method is “target encoding”, which consists of replacing categories with statistical values of the target variable. For example, we can use the average of the target variable values for each category. This simple approach should be avoided, as it will lead to data leakage: the test data will contain information from the training data. Several methods are possible to solve this problem, such as partitioning the training data [14].
CatBoost uses a target encoding strategy described as more effective by the founding paper. Simply put, CatBoost encodes categories based solely on previously observed values. This means that CatBoost applies category encoding sequentially, thus avoiding any target leakage. Since the order of the categories is important, this approach is called “ordered target statistics” or “ordered target encoding”. The numerical value of the category will then be calculated as the average of past observations for that category, smoothed by a constant (=prior) such that the value of category at index is written as [14]:
With the set of indices preceding the index where is 1 for category (when the target is continuous, we simply use statistical intervals/bins).
During inference, the categories are encoded by taking all the previously encoded values.
Ordered Boosting
Just like ordered encoding for processing categorical variables, ordered boosting is motivated by the presence of target leakage during training. Indeed, the authors of the original CatBoost paper show that in a simple case where the same dataset is used to train each tree, a bias inversely proportional to the size of the dataset shifts the prediction. This stems from the use of the same target variables for gradient estimation and tree training. Indeed, we compute the using the target and the prediction , whereas the tree was itself built using . This is a target leakage that causes a shift in the conditional distribution of the gradients (and therefore ) relative to that on the test data and ultimately leads to a biased prediction and a model that generalises less well. To solve this, CatBoost uses ordered boosting [14].

Ordered boosting suggests to solve the leakage issue by using previous examples to train . Thus, has never seen the example and the will not be estimated with a biased . This approach is the same as the one used for ordered encoding by processing the data sequentially, row by row [14].
The naive or brute force implementation of ordered boosting would consist of training n (=number of examples/observations, ) models , such that model is trained only on the i-th observations of a random permutation of the data set. Then, model is used to calculate . However, this naive solution is too complex: training n models would be too costly in terms of time and memory. To reduce the complexity of the implementation and use ordered boosting, CatBoost proceeds as follows [14].
First, CatBoost generates a set of random permutations of the data set, on which to perform ordered encoding and then train each tree. Thus, the gradients and categorical variables will be calculated using a different history at each boosting step . This still ensures that no model has seen the example for which the gradient is calculated, but reduces instability due to the fact that an example at the beginning of the permutation would have very little previous data [14].
Next, CatBoost trains its weak learners, which are symmetric or oblivious decision trees, i.e. trees in which all leaves at a level have the same split/division criterion. These trees are less prone to overfitting and significantly speed up execution at test time. The trees are trained sequentially, where the gradient is calculated using the prediction of the i-th example using the first j-th examples of permutation r. In practice, instead of keeping all predictions , CatBoost only keeps intermediate predictions at geometric intervals (at indices ). This is possible thanks to the symmetric structure of the trees. Thus, if there are s permutations, then the complexity of updating the models and computing the gradients goes from to [14].
e. NODE
f. LSTM
g. GRU
h. Hyperparameters
i. Training
7. Confidence Bands
8. SHAP
9. Evaluation
10. Roadmap
11. Built With
Thanks to all the developers who made these cool open source tools <3
Python Backend










Vue.js Frontend



12. Sources
[1] Chai, S., Li, Q., Abedin, M. Z., & Lucey, B. M. (2024). Forecasting electricity prices from the state-of-the-art modeling technology and the price determinant perspectives. Research in International Business and Finance, 67, 102132.
[2] Kim, J., Kim, H., Kim, H., Lee, D., & Yoon, S. (2025). A comprehensive survey of deep learning for time series forecasting: architectural diversity and open challenges. Artificial Intelligence Review, 58(7), 1-95.
[3] O’Connor, C., Bahloul, M., Prestwich, S., & Visentin, A. (2025). A Review of Electricity Price Forecasting Models in the Day-Ahead, Intra-Day, and Balancing Markets. Energies, 18(12), 3097.
[4] EPEX SPOT. (2025). Basics of the power market.
[5] Geissmann, T., & Obrist, A. (2018). Fundamental Price Drivers on Continental European Day-Ahead Power Markets. Available at SSRN 3211339.
[6] Challu, C., Olivares, K. G., Oreshkin, B. N., Ramirez, F. G., Canseco, M. M., & Dubrawski, A. (2023, June). Nhits: Neural hierarchical interpolation for time series forecasting. In Proceedings of the AAAI conference on artificial intelligence (Vol. 37, No. 6, pp. 6989-6997).
[7] Oreshkin, B. N., Carpov, D., Chapados, N., & Bengio, Y. (2019). N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv preprint arXiv:1905.10437.
[8] Olivares, K. G., Challu, C., Marcjasz, G., Weron, R., & Dubrawski, A. (2023). Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx. International Journal of Forecasting, 39(2), 884-900.
[9] Bergstra, J., Bardenet, R., Bengio, Y., & Kégl, B. (2011). Algorithms for hyper-parameter optimization. Advances in neural information processing systems, 24.
[10] Chen, J., Xiao, J., & Xu, W. (2024, August). A hybrid stacking method for short-term price forecasting in electricity trading market. In 2024 8th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE) (pp. 1-5). IEEE.
[11] Brownlee, J. (2021). Stacking Ensemble Machine Learning With Python.
[12] Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[13] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., … & Liu, T. Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
[14] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: unbiased boosting with categorical features. Advances in neural information processing systems, 31.